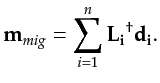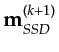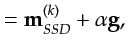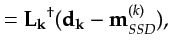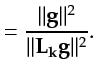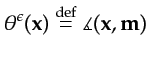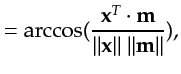Next: Resolution Properties of an Up: Thesis Previous: The Relative Computational Cost Contents
Given a set of sampled Hessians (or equivalently sampled modeling operators) and the associated data generated
according to an underlining model ![]() , I investigate two strategies, with the knowledge
of these sampled Hessians and observed data, to get an estimate of
, I investigate two strategies, with the knowledge
of these sampled Hessians and observed data, to get an estimate of ![]() :
1) migration and 2) successive steepest descent (SSD).
The question I intend to address is, which strategy is better in terms of producing a more accurate estimate?
:
1) migration and 2) successive steepest descent (SSD).
The question I intend to address is, which strategy is better in terms of producing a more accurate estimate?
Let
![]() and
and
![]() respectively be the
respectively be the ![]() copies of
sampled modeling operators
and the data generated according to
copies of
sampled modeling operators
and the data generated according to
 .
.
To fairly evaluate the model error, I introduce
Unable to establish a mathematical bound on
![]() in comparison to
in comparison to
![]() , I resort to a Monte Carlo method instead.
In this study,
, I resort to a Monte Carlo method instead.
In this study,
![]() and
and
![]() .
The sizes are
deliberately chosen
to make each individual inverse problem, i.e., to invert equation D.1, which is underdetermined.
In addition, the performance of the two strategies in the presence of noise is probed. Specifically,
a line of code
.
The sizes are
deliberately chosen
to make each individual inverse problem, i.e., to invert equation D.1, which is underdetermined.
In addition, the performance of the two strategies in the presence of noise is probed. Specifically,
a line of code
![\includegraphics[width=5in]{fig/scatterPlots_StpDesc_vs_mig}](img566.png) |
The results are summarized in Figure D.1. Here, the
![]() 's and
's and ![]() are generated using a Gaussian distribution.
I have varied the types of distribution, from Gaussian to a sparse distribution such as binomial,
and qualitatively the same trends are observed:
SSD produces smaller model error than migration does, except for a few rare exceptions.
As the size of the random set grows (i.e., more stackings in migration and more updates in SSD), the advantage of SSD becomes even more apparent. As plotted in the upper right panel,
are generated using a Gaussian distribution.
I have varied the types of distribution, from Gaussian to a sparse distribution such as binomial,
and qualitatively the same trends are observed:
SSD produces smaller model error than migration does, except for a few rare exceptions.
As the size of the random set grows (i.e., more stackings in migration and more updates in SSD), the advantage of SSD becomes even more apparent. As plotted in the upper right panel,
![]() .
When
.
When
![]() 's are corrupted by noise, however, the performance of SSD deteriorates more than
that of migration. But at this level of noise in most cases SSD still outperforms migration.
's are corrupted by noise, however, the performance of SSD deteriorates more than
that of migration. But at this level of noise in most cases SSD still outperforms migration.
These observations are intuitively understandable. Migration can be thought of as one step of
steepest descent starting from ![]() . Over a set of
. Over a set of ![]() samples, migration amounts to
averaging n attempts of steepest descent, each starting from
samples, migration amounts to
averaging n attempts of steepest descent, each starting from ![]() , whereas in
SSD, the trial model keeps improving. So it's very probable that the latter outperforms the former.
It could happen that the average of these `first attempts' comes very close to the true model.
This explains why exceptions exist.
In the presence of white noise, averaging with equal weight over random instances,
as migration does, is the most effective means to reduce noise.
In SSD, however, the earlier updates influence the iteration trajectory more than the later updates do.
In effect, the end result senses a weighted average of the noise contained in each update, with larger
weight assigned to early samples and smaller weight to later samples, resulting in less noise reduction
than what migration is capable of.
, whereas in
SSD, the trial model keeps improving. So it's very probable that the latter outperforms the former.
It could happen that the average of these `first attempts' comes very close to the true model.
This explains why exceptions exist.
In the presence of white noise, averaging with equal weight over random instances,
as migration does, is the most effective means to reduce noise.
In SSD, however, the earlier updates influence the iteration trajectory more than the later updates do.
In effect, the end result senses a weighted average of the noise contained in each update, with larger
weight assigned to early samples and smaller weight to later samples, resulting in less noise reduction
than what migration is capable of.