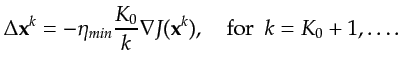Next: Results of the GOM Up: GOM Streamer Dataset Previous: GOM Streamer Dataset Contents
![\includegraphics[width=5in]{fwi_fig/freq2Src_assign}](img315.png) |
To achieve this end, I introduce repellent Coulomb forces between 2D point charges, each point
![]() denoting a mapping from
denoting a mapping from
![]() to source
to source ![]() . This electrostatic system then settles, simulated through greedy optimization, into a low-energy configuration, in which all charged points spread out as much as possible. Examples of this encoding strategy are shown in the left column of Figure 3.8, which appear more uniformly distributed than the counterparts of the standard random permutation shown in the right column.
. This electrostatic system then settles, simulated through greedy optimization, into a low-energy configuration, in which all charged points spread out as much as possible. Examples of this encoding strategy are shown in the left column of Figure 3.8, which appear more uniformly distributed than the counterparts of the standard random permutation shown in the right column.
As the specific frequency-selection code changes over iterations of FWI, this falls in the realm of stochastic optimization (Spall, 2003).
While the convergence of a line search in stochastic optimization is still a research problem, I adopt a hybrid approach.
Run a gradient descent method with line search for the first ![]() iteration steps of FWI,
then switch to a stochastic gradient descent method, where the step size
iteration steps of FWI,
then switch to a stochastic gradient descent method, where the step size
![]() ,
, ![]() being the iteration step index.
This is a lightweight and robust algorithm that converges almost surely to a local minimum (Kiwiel, 2001).
The problem remains in choosing the appropriate constant coefficient for this step size formula.
The recipe is, first, identify the smallest
being the iteration step index.
This is a lightweight and robust algorithm that converges almost surely to a local minimum (Kiwiel, 2001).
The problem remains in choosing the appropriate constant coefficient for this step size formula.
The recipe is, first, identify the smallest ![]() ,
,
![]() , resulting from the first
, resulting from the first ![]() steps of line search,
expressed in the form
steps of line search,
expressed in the form
As mentioned at the end of Section 3.2, 5 function evaluations are required on average by Brent's method for line search.
In contrast, none is required in a stochastic gradient descent method. Consequently, per iteration step of the latter method, the
computational cost is only due to the gradient computation, which requires,
with the transient-reduction scheme, ![]() FDTD propagation steps. This compares to
FDTD propagation steps. This compares to ![]() in the standard approach,
which, taking advantage of the CG method, needs an accurate line search, and therefore explains the associated overhead.
This lightweight stochastic gradient descent approach translates to more iterations and therefore
more frequency-selection codes in use.
in the standard approach,
which, taking advantage of the CG method, needs an accurate line search, and therefore explains the associated overhead.
This lightweight stochastic gradient descent approach translates to more iterations and therefore
more frequency-selection codes in use.
To further reduce the amount of stochasticity in the gradient, we empirically adopt averaging of two successive gradient calculations. Namely, perform the multisource encoding and gradient computation twice, then stack the gradients. This will double the computational cost. So a tradeoff exists between the size of the number of gradients in the average and the convergence speed of the stochastic gradient descent. This averaging (also known as the mini-batch) scheme applies to all 8 supergathers, which are formed by dividing up the 496 shot gathers.
I start the inversion with the data bandpass filtered from 0-6 Hz. The initial velocity model is
decimated to a grid size of
![]() .
At later iterations the band is widened to 15 Hz, and the model is upsampled (with interpolation) to
.
At later iterations the band is widened to 15 Hz, and the model is upsampled (with interpolation) to
![]() .
Finally the frequency band covers 0 to 25 Hz, and the velocity model is of grid size
.
Finally the frequency band covers 0 to 25 Hz, and the velocity model is of grid size
![]() .
I only use standard FWI for the first two cases, because the amount of computation is negligible
compared to the third case. For example, the second case has a quarter of the model size, half of the time samples
(because of doubled time sampling interval), and half the number of shots (due to downsampling). Therefore the computational load per iteration of the second case is only
.
I only use standard FWI for the first two cases, because the amount of computation is negligible
compared to the third case. For example, the second case has a quarter of the model size, half of the time samples
(because of doubled time sampling interval), and half the number of shots (due to downsampling). Therefore the computational load per iteration of the second case is only ![]() of the third.
of the third.
Yunsong Huang 2013-09-22